RunaBase
Administrator
To transfer data from external sources to RunaBase, you need to use import from a text file with the .csv extension . This file can be obtained in the most popular office applications: MS Excel, OpenOffice / LibreOffice Calc and others, setting the appropriate type when saving the file.
The data separator in the .csv file is the symbol that is defined in the system settings (e.g, for Windows: "Control Panel" - "Language and Regional Standards" - "Formats" tab - "Additional formats" button - "Numbers" tab - "List element separator" property) . You can override the separator directly in Runabase by setting a different value in the program settings ("Advanced" tab, "CSV Separator" parameter).
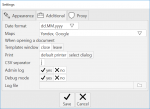
Import / export of data is possible only in the object, in exclusive (individual) access mode, with network access to the project turned off. In multi-user mode, these operations are automatically disabled, blocking users from receiving a large amount of data from the database in an unauthorized way.
For correct text recognition, the .csv file must be saved in one of the encodings, a list of which is defined for each language installed in the RunaBase constructor. By default, when importing from a file, universal UTF-8 encoding will be offered for all languages. But since some programs save data in the national encoding (for example, Excel sets Windows-1251 for the Russian language by default), then when importing, you may have to choose the appropriate encoding. You may convert the contents of the import file to one of the required encodings, for example, to UTF-8, - using various text editors, e.g Notepad ++ ("Encodings" - "Convert to UTF-8").
Also, for correct text recognition, the .csv file must comply with RFC 4180 standard. Admittedly, not all of the examples of .csv file found on the Internet correspond to it.
Although the header line is optional by the standard, it is needed for the Runabase. The correspondence of the data columns in the file and the fields in the object is determined by the header, which is the first line of the import file. The match must be case sensitive. Otherwise, the data column will be skipped. To quickly get the list of fields in the header, in the constructor object, you can export to the .csv file and extract the title names from the received file. The order of the columns in the import file does not matter - all the data will be brought back to the order specified in the object.
If the object contains Link fields to other objects, records will be created in these objects with the corresponding key fields (if there were none), and links to newly created (or existing) records will be added in the object itself. Therefore, when importing data for several related tables, the sequence of this operation does not matter: after creating records in another object, you can import the rest of the information by specifying in the import parameter “Action” the value “replace” records with a repeating first field.
Here is an example of import into a database using very simple project as an example - home library.
We created two objects - Book and Author. Author contains one string field - "Full name", Book contains string field "Title", link field "Author", and string field "Weblink" of the corresponding subtype.
He original csv file, found on the Internet, required some improvements. First of all, we add header line:
Then, we need to use CR/LF, not just LF separator, because the file doesn't comply RFC 4180 standard. To do this, we will re-save the file in Openoffice Calc.
After that, you will only need to open RunaBase, click Import button in the Book object and select the file to import data. In the preview window, the first 100 entries from the file are displayed, which allow you to determine the correct encoding and the correspondence of the columns with the data fields in the object.
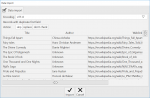
The "Action" property in the import settings window affects the way of adding records to the database, determined by the first (key) field:
- "skip": if the key field is in the database, then import of the record is skipped;
- “replace”: if the key field is in the database, then the record in the database is replaced with data from the import file;
- "do not check": the existence of duplicates in the database is not checked.
When importing with the first and second conditions, each line of the file is checked for repetition in the database, which can significantly slow down the import process. To quickly perform the operation, when it is known that all records are unique, it is advisable to set the "Action" property to "do not check".
After the import is complete, we will see that entries were added as to the Book object, and to the Author object as well.
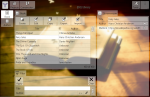
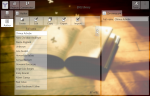
Recommendation: when importing a large number of records, first create a project archive. This will help you to return to the original database version, if necessary.
The data separator in the .csv file is the symbol that is defined in the system settings (e.g, for Windows: "Control Panel" - "Language and Regional Standards" - "Formats" tab - "Additional formats" button - "Numbers" tab - "List element separator" property) . You can override the separator directly in Runabase by setting a different value in the program settings ("Advanced" tab, "CSV Separator" parameter).
Import / export of data is possible only in the object, in exclusive (individual) access mode, with network access to the project turned off. In multi-user mode, these operations are automatically disabled, blocking users from receiving a large amount of data from the database in an unauthorized way.
For correct text recognition, the .csv file must be saved in one of the encodings, a list of which is defined for each language installed in the RunaBase constructor. By default, when importing from a file, universal UTF-8 encoding will be offered for all languages. But since some programs save data in the national encoding (for example, Excel sets Windows-1251 for the Russian language by default), then when importing, you may have to choose the appropriate encoding. You may convert the contents of the import file to one of the required encodings, for example, to UTF-8, - using various text editors, e.g Notepad ++ ("Encodings" - "Convert to UTF-8").
Also, for correct text recognition, the .csv file must comply with RFC 4180 standard. Admittedly, not all of the examples of .csv file found on the Internet correspond to it.
Although the header line is optional by the standard, it is needed for the Runabase. The correspondence of the data columns in the file and the fields in the object is determined by the header, which is the first line of the import file. The match must be case sensitive. Otherwise, the data column will be skipped. To quickly get the list of fields in the header, in the constructor object, you can export to the .csv file and extract the title names from the received file. The order of the columns in the import file does not matter - all the data will be brought back to the order specified in the object.
If the object contains Link fields to other objects, records will be created in these objects with the corresponding key fields (if there were none), and links to newly created (or existing) records will be added in the object itself. Therefore, when importing data for several related tables, the sequence of this operation does not matter: after creating records in another object, you can import the rest of the information by specifying in the import parameter “Action” the value “replace” records with a repeating first field.
Here is an example of import into a database using very simple project as an example - home library.
We created two objects - Book and Author. Author contains one string field - "Full name", Book contains string field "Title", link field "Author", and string field "Weblink" of the corresponding subtype.
He original csv file, found on the Internet, required some improvements. First of all, we add header line:
Title;Author;Year;Year;Country;Language;Pages;Logo;WeblinkThen, we need to use CR/LF, not just LF separator, because the file doesn't comply RFC 4180 standard. To do this, we will re-save the file in Openoffice Calc.
After that, you will only need to open RunaBase, click Import button in the Book object and select the file to import data. In the preview window, the first 100 entries from the file are displayed, which allow you to determine the correct encoding and the correspondence of the columns with the data fields in the object.
The "Action" property in the import settings window affects the way of adding records to the database, determined by the first (key) field:
- "skip": if the key field is in the database, then import of the record is skipped;
- “replace”: if the key field is in the database, then the record in the database is replaced with data from the import file;
- "do not check": the existence of duplicates in the database is not checked.
When importing with the first and second conditions, each line of the file is checked for repetition in the database, which can significantly slow down the import process. To quickly perform the operation, when it is known that all records are unique, it is advisable to set the "Action" property to "do not check".
After the import is complete, we will see that entries were added as to the Book object, and to the Author object as well.
Recommendation: when importing a large number of records, first create a project archive. This will help you to return to the original database version, if necessary.
Attachments
-
767 bytes Views: 12
-
13.5 KB Views: 10